
organizing data for modeling principles and applications
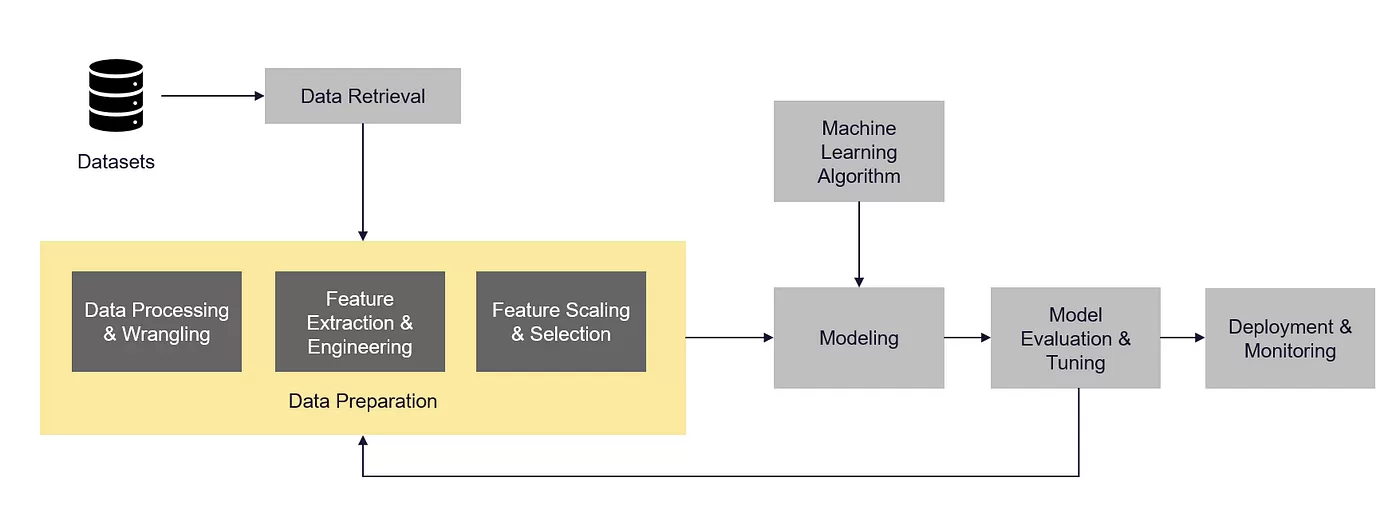
When organizing data for modeling principles and applications, there are several important considerations to keep in mind. Here are some steps you can follow to effectively organize your data:
Define the problem: Clearly understand the problem you are trying to solve or the goal you want to achieve with your modeling. This will help guide your data organization efforts.
Identify relevant data sources: Determine the sources of data that are relevant to your problem. This could include structured data from databases, spreadsheets, or APIs, as well as unstructured data like text documents, images, or videos.
Data collection:
Gather the data from the identified sources. This may involve web scraping, data entry, or accessing pre-existing datasets. Ensure that you have the necessary permissions and legal rights to use the data.
Data preprocessing:
Clean and preprocess the data to ensure its quality and suitability for modeling. This step may involve handling missing values, removing duplicates, standardizing formats, and transforming variables as needed. Additionally, consider normalizing or scaling numerical features to ensure they are on a comparable scale.
Split the data:
Divide your dataset into training, validation, and testing sets. The training set is used to train the model, the validation set helps tune hyperparameters and evaluate model performance during development, and the testing set is used for the final evaluation of the model’s performance.
Feature engineering:
Create new features or derive meaningful representations from the existing data that can enhance the predictive power of your model. This could involve techniques such as one-hot encoding, feature scaling, dimensionality reduction, or text tokenization.
Data storage and organization:
Set up a proper data storage system that allows easy access and retrieval of data during modeling. This could include using databases, file systems, or cloud storage solutions. Maintain clear documentation of the data sources, preprocessing steps, and any transformations applied.
Data labeling and annotation:
If your problem requires labeled data, such as in supervised learning, ensure that you have a process in place to annotate or label the data accurately and consistently. This may involve manual labeling or using automated techniques like crowdsourcing or pre-trained models.
Data versioning and tracking:
Implement a system to track and version your data during the modeling process. This is crucial for reproducibility and ensuring that you can trace back to the specific dataset used for a particular model or experiment.
Data privacy and security:
Be mindful of data privacy and security considerations. Ensure that sensitive or personally identifiable information is handled appropriately and in compliance with applicable regulations.
By following these steps, you can effectively organize your data for modeling principles and applications, setting a solid foundation for building robust and accurate models.
What are some common challenges in data preprocessing for modeling?
Data preprocessing is a crucial step in the data modeling pipeline, and it often presents several challenges that need to be addressed. Here are some common challenges encountered during data preprocessing:
Missing data:
Datasets may contain missing values, which can impact the performance of models. Handling missing data involves making decisions on how to impute or remove missing values while preserving the integrity and representativeness of the data.
Outliers:
Outliers are data points that deviate significantly from the normal distribution of the dataset. Outliers can adversely affect the performance of models by introducing noise or bias. Deciding whether to remove outliers or handle them differently requires careful consideration.
Feature scaling:
Features in the dataset may have different scales or units, which can affect the performance of certain models, such as those based on distance calculations or optimization algorithms. Scaling techniques like standardization or normalization may be required to bring features to a comparable scale.
Categorical variables:
Many machine learning algorithms require numerical inputs, so categorical variables need to be encoded appropriately. One-hot encoding, label encoding, or ordinal encoding techniques can be used, but selecting the right approach depends on the nature of the data and the specific modeling requirements.
Feature engineering:
Generating informative and relevant features from the raw data can be challenging. It requires domain knowledge, creativity, and experimentation to extract meaningful information that captures the underlying patterns and relationships in the data.
Dimensionality reduction:
High-dimensional datasets can pose challenges for modeling due to increased computational complexity, overfitting, and the curse of dimensionality. Techniques like principal component analysis (PCA) or feature selection methods are employed to reduce the dimensionality of the dataset while preserving important information.
Data normalization:
Data may exhibit skewed distributions or have different statistical properties. Normalizing the data using techniques like logarithmic transformation or box-cox transformation can help make the data conform to assumptions made by certain models and improve their performance.
Time series data:
When working with time series data, additional preprocessing steps may be required, such as handling temporal dependencies, resampling, or aggregating data at different time intervals. Dealing with irregular time intervals or missing time points can also be challenging.
Data integration:
If data is collected from multiple sources, integrating and merging the data can be complex. Ensuring consistency across different datasets, resolving conflicts, and dealing with variations in data formats or semantics are common challenges in data integration.
Computational efficiency:
Preprocessing large datasets can be computationally intensive and time-consuming. Efficient data preprocessing techniques, such as parallel processing or streaming data processing, may be required to handle big data scenarios.
Addressing these challenges requires careful consideration, domain knowledge, and a thorough understanding of the data and modeling techniques. It is important to experiment, iterate, and validate the preprocessing steps to ensure the quality and integrity of the data for subsequent modeling tasks.
Can you provide examples of feature engineering techniques for organizing data?
Certainly! Feature engineering involves creating new features or transforming existing features to improve the predictive power of a model. Here are some common feature engineering techniques that can be used to organize data:
Polynomial features:
In some cases, the relationship between features and the target variable may not be linear. Introducing polynomial features by squaring or multiplying existing features can capture non-linear relationships and improve model performance.
Interaction features:
Interaction features are created by combining two or more existing features. For example, if you have features representing height and weight, you can create an interaction feature by multiplying these two together. This can capture synergistic effects between features and provide additional information to the model.
Binning:
Binning involves dividing a continuous feature into discrete bins or intervals. This can help capture non-linear relationships or patterns that may not be evident in the raw continuous data. Binning can be useful when there is limited data or when certain ranges of values have specific significance.
One-Hot Encoding:
One-hot encoding is used to represent categorical variables as binary vectors. Each category is converted into a binary feature, where a value of 1 indicates the presence of that category and 0 indicates its absence. This allows categorical variables to be used as input in models that require numerical data.
Ordinal Encoding:
Ordinal encoding is used when there is an inherent order or ranking among the categories of a categorical variable. Each category is assigned a unique numerical value based on its order or importance. This preserves the ordinal relationship between categories and can be useful in certain modeling scenarios.
Target Encoding:
Target encoding, also known as mean encoding, replaces categorical variables with the mean target value of each category. This can help capture the relationship between categorical variables and the target variable, especially when there are a large number of categories.
Time-based features:
If your dataset contains timestamps or time-related information, you can extract various time-based features such as day of the week, month, hour of the day, or time since a specific event. These features can help capture temporal patterns and seasonality in the data.
Text-based features:
When working with text data, you can extract features such as word counts, n-grams, or term frequency-inverse document frequency (TF-IDF) values. These features can represent the presence or importance of specific words or phrases in the text and can be used for tasks like text classification or sentiment analysis.
Aggregation features:
Aggregating data at different levels of granularity can provide additional insights. For example, if you have transaction data, you can create features such as total sales per customer, average purchase amount per day, or maximum purchase value per product. These aggregated features can capture higher-level patterns and summaries of the data.
Domain-specific features:
Depending on the problem domain, there may be specific features that are relevant and informative. These features can be derived from domain knowledge and expertise. For example, in a healthcare setting, features like body mass index (BMI), disease-specific indicators, or clinical scores can be useful.
These are just a few examples of feature engineering techniques. The choice of techniques depends on the specific dataset, problem domain, and modeling goals. It’s important to carefully analyze the data, understand the relationships between features, and iteratively experiment with different feature engineering approaches to find the most effective representation of the data for modeling tasks.

